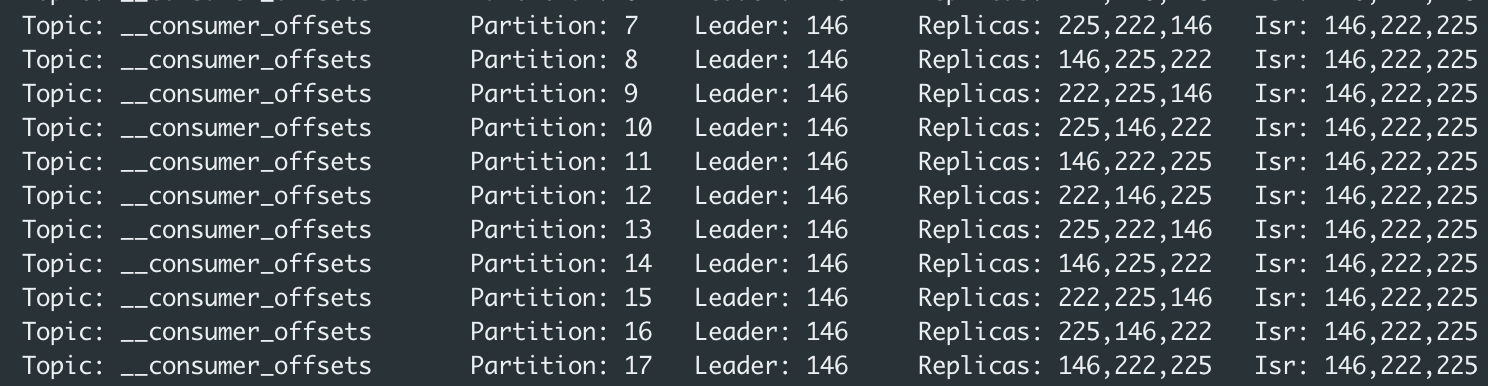
原文地址:http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-writing-to-ring.html(因被墙移到墙内)
作者:Trisha
这是disruptor端到端视图中缺失的部分。撑住,这相当长!
要点:
生产者屏障
disruptor 源码中有消费者的接口和帮助类,但是没有生产者接口。因为你只需要了解生产者,而不需要额外的访问。像消费端一样, ring buffer 创建了一个生产者屏障,生产者使用 producer barrier 写入数据到 ring buffer。
写入 ring buffer 涉及到两阶段提交。首先,生产者必须申明 ring buffer 中下一个插槽的所有权;之后,当生产者完成对该插槽的写入,它将提交事物到 producer barrier 。
我们先看第一步。“给我 ring buffer 的下一个插槽”,这听起来很简单。确实,从生产者角度来看这确实简单。只需要调用 producer barrier 的 nextEntry() 方法,就会给你返回下一个插槽的实体对象。
生产者屏障保证ring buffer不重叠
表层之下,producer barrier 确认了下一个插槽是啥,并且你是否有权限写入。
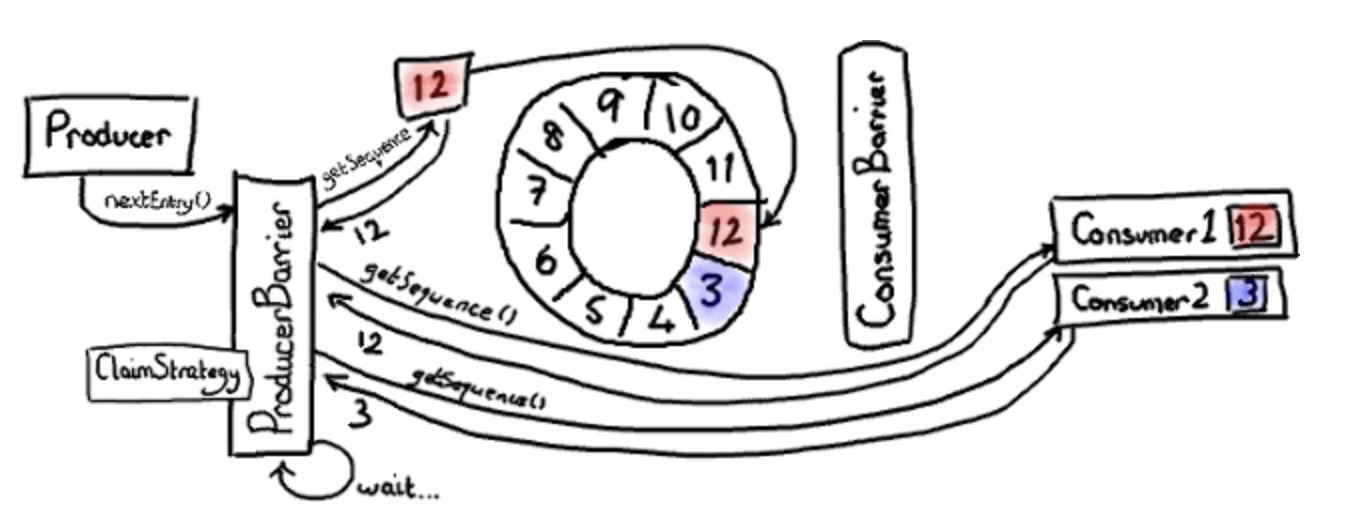
在上图中,我们假设只有一个生产者写入 ring buffer 。随后,我们会来处理复杂的多生产者模式。
ConsumerTrackingProducerBarrier 持有一系列访问 ring buffer 的消费者。对于我来说,现在看起来有点奇怪。我不想在 producer barrier 关心消费端。不过,这是有原因的。我们不希望队列存在归并关系,我们的消费者有责任知道自己的关心的序列号。所以,如果我们想确认我们没有重叠缓存,我们必须检查消费者的消费位置。
上图中,一个消费者恰巧位于最高序列号12;另一个消费者滞后一些,位于序列号3,可能在执行IO等等。因此,消费者2在赶上消费者1之前,需要消费整个缓冲区长度的消息。
生产者想向 ring buffer 中当前被序列号3占据位置写入数据,因为这个插槽刚好在 ring buffer 当前指针之后。当时 producer barrier 知道它当前并不能写入,因为有一个消费者正在使用它。然后 producer barrier 只能停下来,自旋,等待该消费者让出插槽。
申明下一个插槽
现在,我们想象一下,消费者2结束那批消息的消费。也许它消费到序列号9的位置(在现实生活中,因为消费者批量消费,往往消费到序列号12的位置。不过,那样的话样例就变得没意思了)
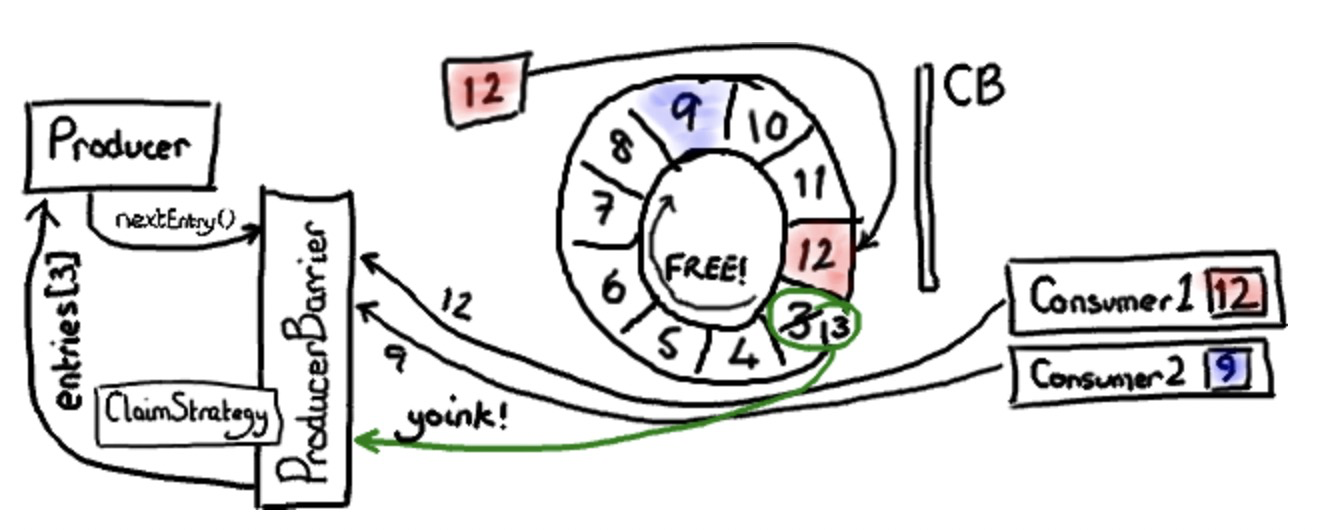
上面这张图演示了消费者2更新到序列号9的情形。因为 consumer barrier 在这里没有作用,我省略它。
producer barrier 看到下一个插槽变得可用。它窃取了插槽中的实体对象(我还没有专门讨论过这个实体类。简要的说,它基本就是一个筐,存放任何你想放进 ring buffer 的,携带序列号的东西)。设置实体序列号为下一个值(13),然后返回实体到生产者。生产者就能写入任何它想写入的东西。
提交新值
两阶段提交的第二阶段,即是提交。 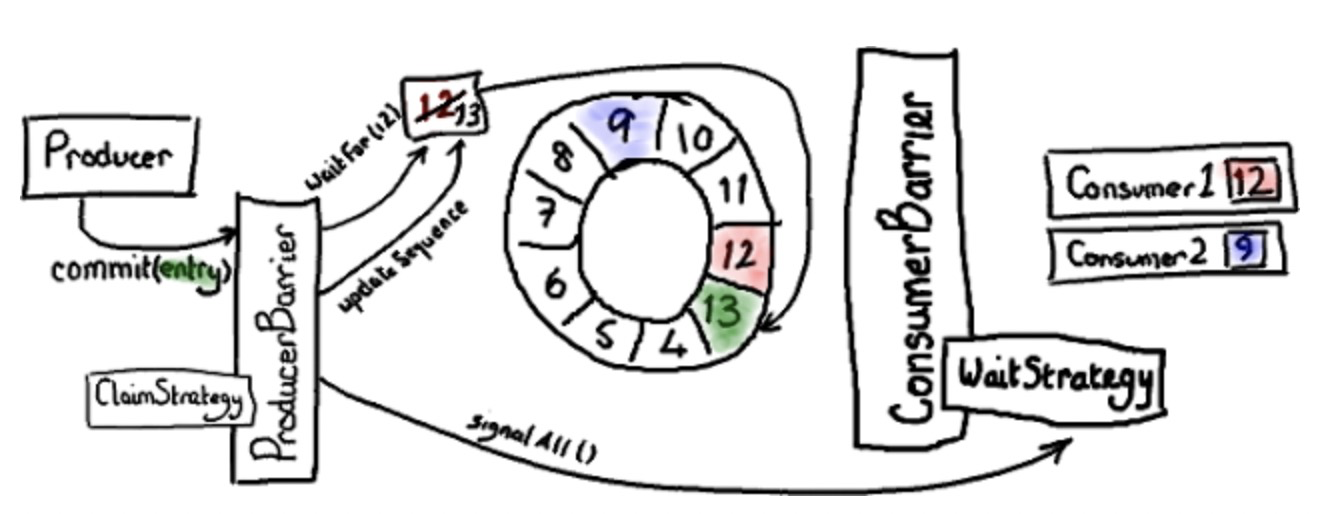
绿色插槽代表我们刚更新的序列号13的实体。
当生产者将消息写入实体,它会通知 producer barrier 去提交。
producer barrier 等待 ring buffer 指针捕获我们的位置(在单生产者时,这是毫无意义的。示例:我们知道指针在序列号12位置,没有什么会再写入该序列号。)producer barrier 更新 ring buffer 指针到序列号13。下一步,producer barrier 告诉消费者新消息已经准备好。这依赖于唤醒 consumer barrier 的 wait strategy “醒醒,有事做了”(根据阻塞与否,不同等待策略实现处理方式不同)。
现在消费者1可以消费实体13,消费者2可以 消费13及之前实体。他们愉快的工作着。
生产者屏障批处理(并发写入)
有趣的是,disruptor 可以处理多个生产者,就像消费者端一样。回想一下,消费者2什么时候执行程序,并发现自己在位置9的?这里 producer barrier 做了一件狡猾的事 - 它知道缓冲区的长度,知道消费最慢的消费者位置。所以,它能知道哪个插槽可用。
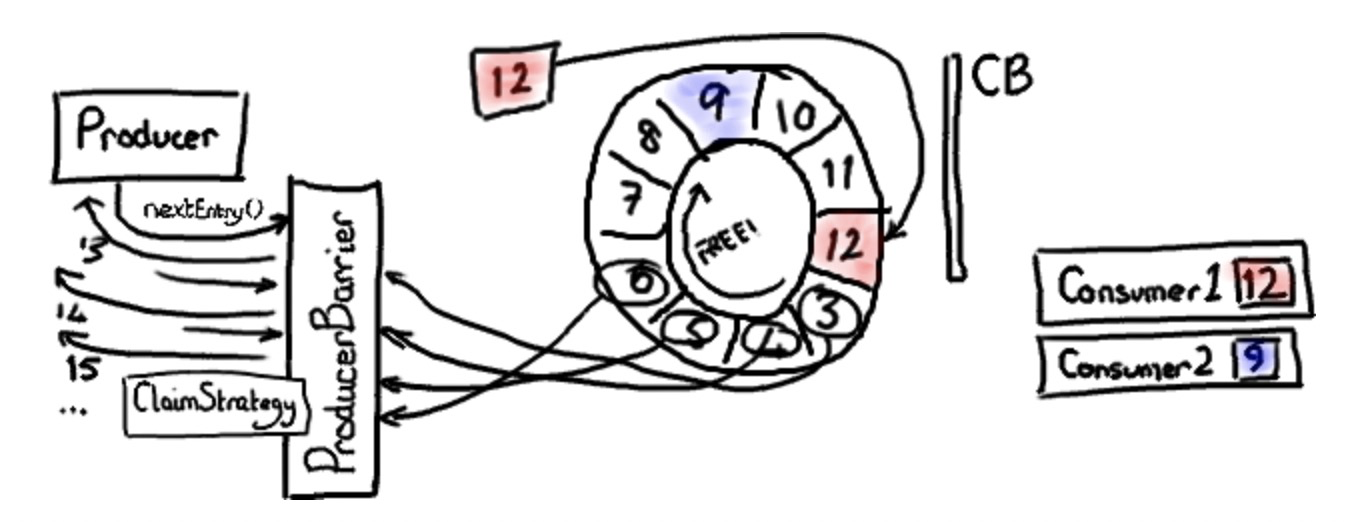
假使 producer barrier 知道 ring buffer 的指针在位置12,最慢的消费者在位置9。它就能让生产者写入插槽3,4,5,6,7,8。
多生产者
你是否觉着我已经考虑完了?实际上这里还有更多。
上面图中我略有撒谎。我暗示 producer barrier 使用的序列号,直接来源于 ring buffer 的指针。然而,如果查看代码,你会发现它使用 claim strategy 来获取序列号。我跳过这里以简化图形,因为它在单生产者中并不重要。
在多生产者中,你需要另一个组件来跟踪可以写入的序列号。注意,这不是 ring buffer 指针➕1那么简单 - 如果你不仅有一个生产者,有些实体可能正在北写入,且没有被提交。
让我们重温申明一个插槽。每一个生产者询问 claim strategy 下一个可用插槽。就像上面单生产者一样,生产者1拿到了序列号13。即使 ring buffer 指针任然指向12,生产者2会拿到序列号14。因为 claim sequence 跟踪已经被分配的序列号。
所以,每个生产者拿到它独占的插槽和崭新的序列号。
我把生产者1和它的插槽标记为绿色;生产者2和它的插槽标记为可疑的粉色。

现在,想象一下生产者1脱离了掌控,处于某种原因未曾提交。生产者2已经准备好提交,询问 producer barrier 是否可以提交。
之前提交图中所示,producer barrier 只有当ring buffer 的指针到达想要提交的插槽后方时,它才会提交。在这个案例中,指针抵达13,我们才能提交14。因为生产者1盯着某些闪光的东西没有提交,我们不能提交14。所以 claim strategy 等在那里直到 ring buffer 指针到达指定位置。

现在生产者1从昏迷中醒来,提交实例13。producer barrier 告诉 claim stratey ring buffer 指针要在12位置。然后 ring buffer 指针增长到13,producer barrier 通知 wait strategy 让消费者们知道 ring buffer 已经更新。此时,producer barrier 才能结束生产者2的请求,ring buffer 指针增长到14,通知所有消费者我们已经更新。
你可以发现,就算生产者结束写入的时间不同,ring buffer 始终保持了初始调用nextEntry() 的顺序。这意味着一旦某个生产者写入时暂停,当它接触锁定后,其他后续提交可以立即执行。
Ps:
- 最新版本中,
ring buffer 隐藏了 producer barrier 。如果你找不到,就当它存在于 ring buffer。
- 2.0版本中,有写类名发生了改变。如果你感到困惑,请参考my summary of changes